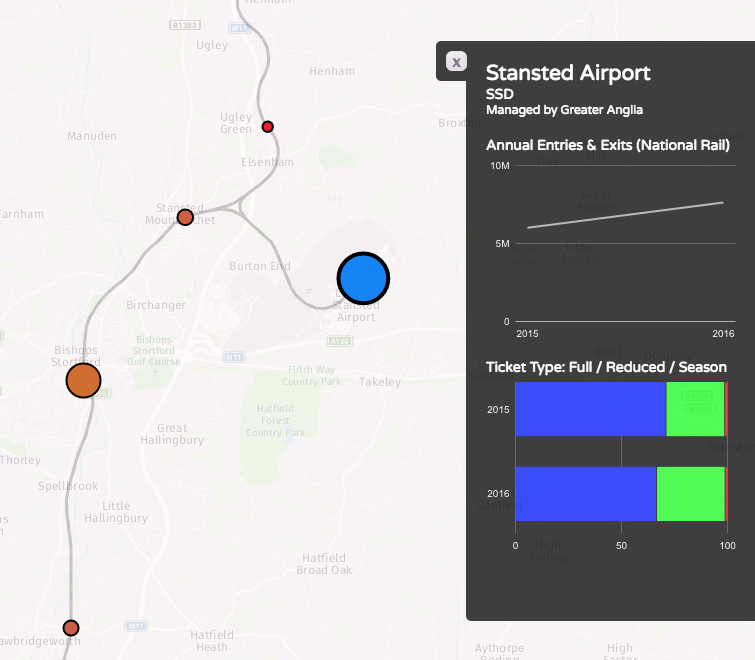
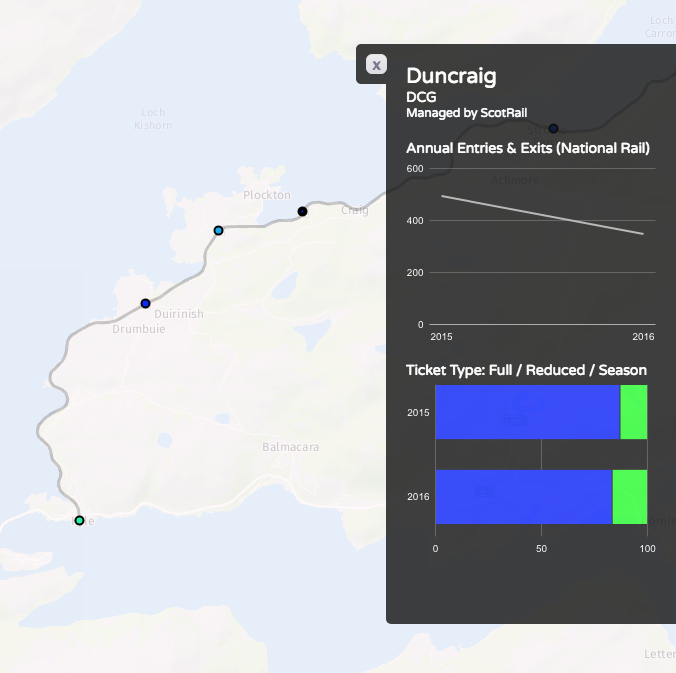
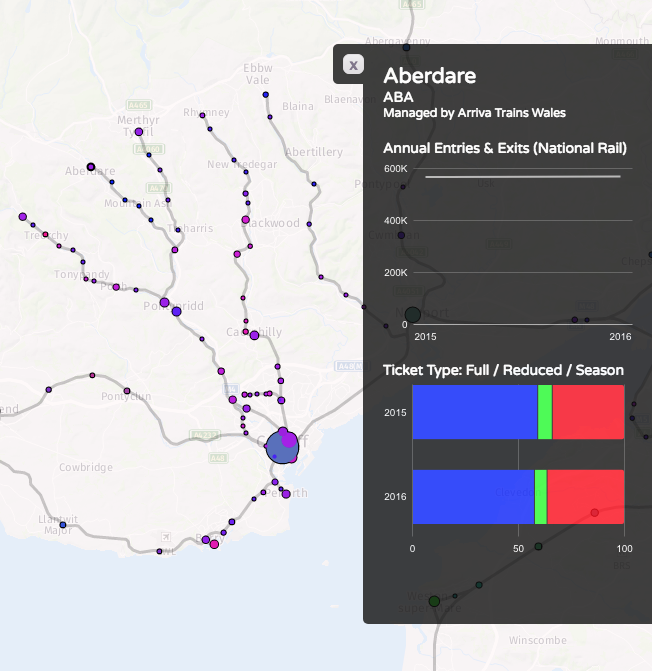
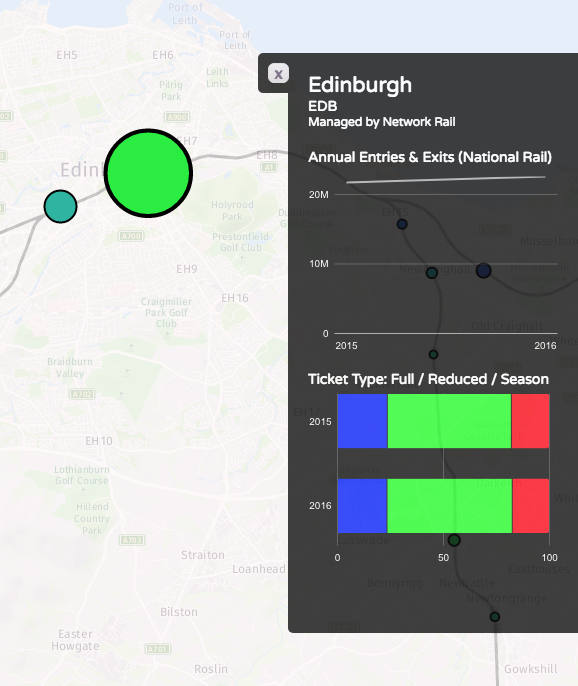
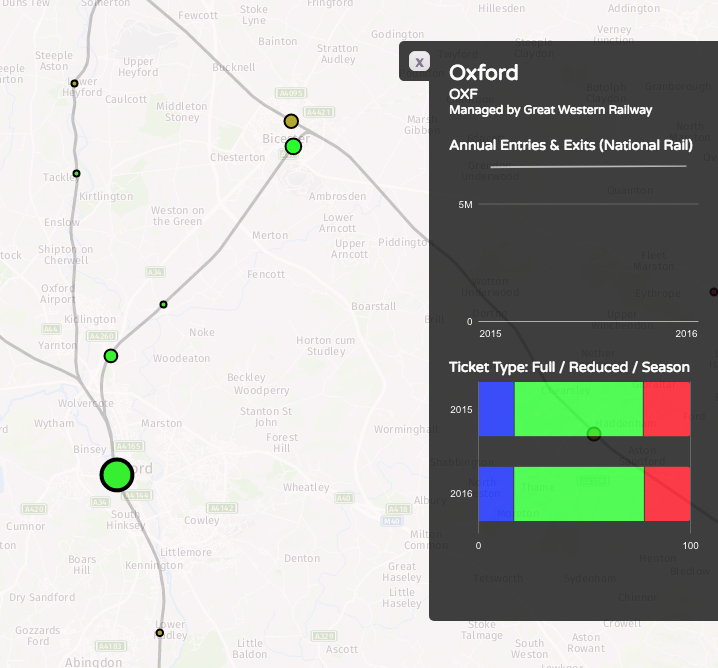
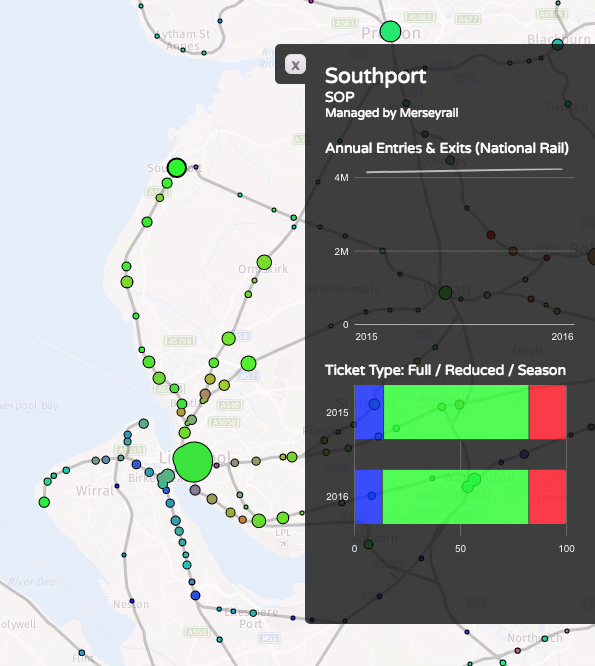
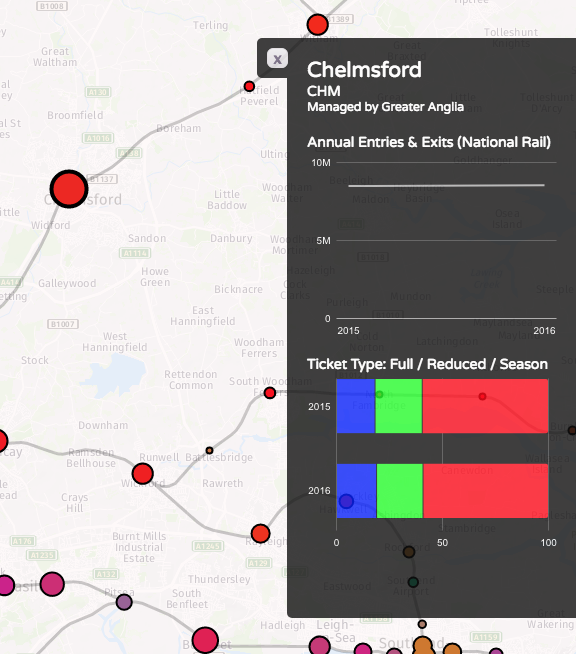
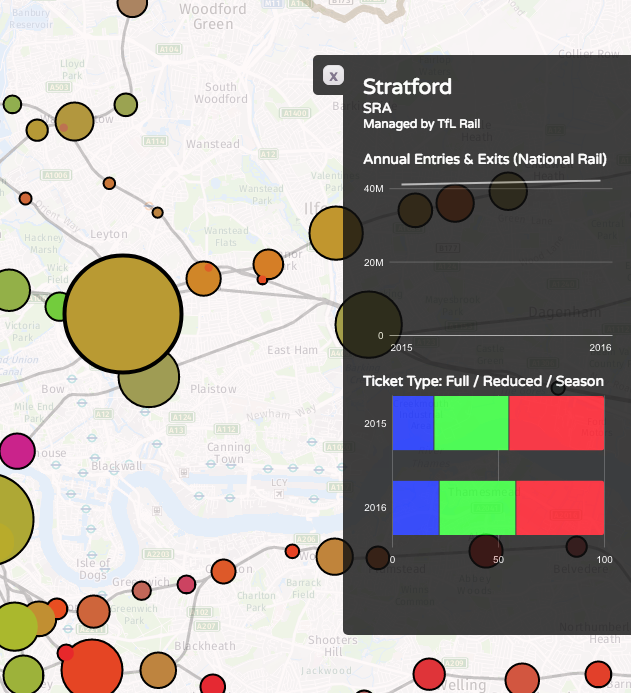
We’ve been seeing some interesting trends developing in researchers’ preferences for certain programming software over others.
When it comes to spatial modelling, building maps and visualising data, ArcGIS has long been considered the front runner. Its intuitive ‘point and click’ interface means that you can build professional looking outputs from scratch without the need for any programming experience.
Some of the stand-out merits of ArcGIS include:
- Its ability to handle a large variety of spatial and non-spatial data formats
- The layout view which allows creation of professional outputs
- The ‘Add data’ button which recognises tables, rasters and all GIS formats
- It’s a great tool for easy visualisation
- The table joins in ArcGIS are intuitive, enabling the linking of spatial and other data
- It handles Coordinate Reference Systems in a user friendly way
- It gives you access to ArcGIS Online (AGOL): a great resource for sourcing a whole range of GIS datasets
- A basic licence in ArcGIS still gives you access to a large number of tools
- It has a variety of purchasable useful plug-ins such as crime analyst
- You’re a shoe-in for creating beautiful maps where titles and legends are far easier to add
- The ArcMap splash screen (i.e. start-up screen) displays all your latest documents
Of course, it is a subscription software and access to full ArcGIS features is determined by the level of your licence. Although the subscription fee can be expensive, ESRI offers award-winning support services and extensive help documentation. At the end of the day, its map-building and visualisation potential is vast and user-friendly.
But could there be another software contending in the race for slick visualisation and professional outputs?
R has been called a “a statistical powerhouse programming language”* which combines a framework of integrated processing, analysis and modelling. It’s perfect for the researcher as all outputs are easily reproducible and seemingly the most popular tool for data mining in business and academia. However, it has a steep learning curve in order to get up to speed with its command programming set-up, which may not be intuitive for non-programmers, though this is immeasurably helped by the use of RStudio.
Some of the hands-down merits of R include:
- It’s open source and therefore supported by a vast online community of users happy to share their wisdom for free
- It’s a superior data analysis tool as it is able to handle large amounts of data
- Its base package includes all standard statistical tests, models and analyses
- It’s versatile in allowing you to manipulate data
- It’s designed to be used with spatial and statistical data
- You can use R to solve complex data science, machine learning and statistical problems
- Geographically weighted regression and spatial interaction models can be custom built around your spatial data in R
The key difference between R and ArcGIS though when it comes to spatial visualisation and mapping is that operations in R are command-centred and therefore visualisations may only be created and edited by altering command codes. R does have an extensive graphics library but creating a professional output can be very time-consuming for a beginner. Once you get the hang of it, this is great, but it is not necessarily as intuitive as ArcGIS. There’s also no dynamic canvas with which to pan and zoom. But on the other hand it is free!
Of course, you can combine R with ArcGIS and get the best of both worlds to become an absolute spatial wizard! There is now the Esri R-ArcGIS bridge which enables you to increase the capabilities of analyses across different disciplines. In real terms it allows you to transfer your data between ArcGIS and R without losing any of the functionality and formatting. Learn more here. Or you might prefer to use QGIS as an alternative to ArcGIS – learn more about the relative merits of ArcGIS and QGIS here.
Co-authored by Rachel Oldroyd
Want to learn more about ArcGIS? Book on our training short course on 19th March with expert Rachel Oldroyd to find out more: https://www.cdrc.ac.uk/events/19725/
Want to learn more about R? Book on our training short course on 16th April with expert Richard Hodgett to find out more: https://www.cdrc.ac.uk/events/introduction-to-r-2/
Continue the debate with us! Let us know what you think @CDRC with the hashtag #ArcGISvsR
*citation: https://blogs.esri.com/esri/arcgis/2016/07/21/put-the-r-in-arcgis-2/